X Files Season Ratings using R
X Files was a favorite TV show of mine as a kid and with the revival coming in 2016, I wanted to take a look at each episode IMDB ratings. Using the OMDb API, we can query each episode in JSON format and extract the needed information. This post will take a look at how to do this using R and packages rjson and ggplot2.
Parsing JSON with R
Loading rjson:
library(rjson)From the OMDb API, a query for X Files season 1, episode 1 is:
http://www.omdbapi.com/?t=X+Files&Season=1&Episode=1
This will return JSON formatted information including: title, IMDB rating, year, release date, response, and more. The first information to check is the Response variable. This is a true/false response, if the query was successful or not. Since using this API, it is not possible to get the number of episodes in a season, we will use the response variable to determine if there are no more episodes to a season.
An example of the query and output is shown below:
fromJSON(file="http://www.omdbapi.com/?t=X+Files&Season=1&Episode=1", method="C")## $Title
## [1] "Deep Throat"
##
## $Year
## [1] "1993"
##
## $Rated
## [1] "TV-14"
##
## $Released
## [1] "17 Sep 1993"
##
## $Season
## [1] "1"
##
## $Episode
## [1] "1"
##
## $Runtime
## [1] "43 min"
##
## $Genre
## [1] "Drama, Mystery, Sci-Fi"
##
## $Director
## [1] "Daniel Sackheim"
##
## $Writer
## [1] "Chris Carter (created by), Chris Carter"
##
## $Actors
## [1] "David Duchovny, Gillian Anderson, Jerry Hardin, Michael Bryan French"
##
## $Plot
## [1] "Agents Mulder and Scully investigate the suspicious behaviour of a secret air force base in Idaho, coming into contact with government forces which threaten their careers and safety."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA"
##
## $Awards
## [1] "N/A"
##
## $Poster
## [1] "http://ia.media-imdb.com/images/M/MV5BODM2NzAwMjgxNF5BMl5BanBnXkFtZTcwNzYwNjkzMQ@@._V1_SX300.jpg"
##
## $Metascore
## [1] "N/A"
##
## $imdbRating
## [1] "8.3"
##
## $imdbVotes
## [1] "2406"
##
## $imdbID
## [1] "tt0751099"
##
## $seriesID
## [1] "tt0106179"
##
## $Type
## [1] "episode"
##
## $Response
## [1] "True"Storing Info
The information will be stored as a data frame using the following columns:
- num - Index from 1 to the total number of episodes
- season - The season from JSON query
- episode - The episode from JSON query
- title - The title of the episode from JSON query
- release - The release date of the episode from JSON query
- rate - The IMDB rating of the episode from JSON query
xf.df <- data.frame(num=NA, season=NA, episode=NA, title=NA, release=NA, rate=NA, stringsAsFactors=F)Gathering the Data
According to IMDB there are 9 seasons of X Files. Using this information and the above, it will be possible to gather the information. This may not be the best way to do it in R but will get the job done.
getURL <- function(curS, curE) {
return(paste("http://www.omdbapi.com/?t=X+Files&Season=", curS, "&Episode=", curE, sep=""))
}
numS <- 9 # Number of season
curS <- 1 # Current season
curE <- 1 # Current episode
idx <- 1 # Current index
while(curS <= numS) {
url <- getURL(curS, curE)
data <- fromJSON(file=url, method="C")
# Loop over episodes while valid
while(data$Response) {
xf.df[idx,] <- NA
xf.df$num[idx] <- idx
xf.df$season[idx] <- data$Season
xf.df$episode[idx] <- data$Episode
xf.df$title[idx] <- data$Title
xf.df$release[idx] <- data$Released
xf.df$rate[idx] <- data$imdbRating
# Get next
idx <- idx + 1
curE <- curE + 1
url <- getURL(curS, curE)
data <- fromJSON(file=url, method="C")
Sys.sleep(0.5) # Pause
}
curS <- curS + 1
curE <- 1
}
library(knitr)
kable(xf.df)| num | season | episode | title | release | rate |
|---|---|---|---|---|---|
| 1 | 1 | 1 | Deep Throat | 17 Sep 1993 | 8.3 |
| 2 | 1 | 2 | Squeeze | 24 Sep 1993 | 8.7 |
| 3 | 1 | 3 | Conduit | 01 Oct 1993 | 7.7 |
| 4 | 1 | 4 | The Jersey Devil | 08 Oct 1993 | 7.1 |
| 5 | 1 | 5 | Shadows | 22 Oct 1993 | 7.3 |
| 6 | 1 | 6 | Ghost in the Machine | 29 Oct 1993 | 6.8 |
| 7 | 1 | 7 | Ice | 05 Nov 1993 | 8.9 |
| 8 | 1 | 8 | Space | 12 Nov 1993 | 6.2 |
| 9 | 1 | 9 | Fallen Angel | 19 Nov 1993 | 8.0 |
| 10 | 1 | 10 | Eve | 10 Dec 1993 | 8.2 |
| 11 | 1 | 11 | Fire | 17 Dec 1993 | 7.4 |
| 12 | 1 | 12 | Beyond the Sea | 07 Jan 1994 | 8.7 |
| 13 | 1 | 13 | Gender Bender | 21 Jan 1994 | 7.5 |
| 14 | 1 | 14 | Lazarus | 04 Feb 1994 | 7.1 |
| 15 | 1 | 15 | Young at Heart | 11 Feb 1994 | 7.4 |
| 16 | 1 | 16 | E.B.E. | 18 Feb 1994 | 8.6 |
| 17 | 3 | 1 | The Blessing Way | 22 Sep 1995 | 8.8 |
| 18 | 3 | 2 | Paper Clip | 29 Sep 1995 | 9.1 |
| 19 | 3 | 3 | D.P.O. | 06 Oct 1995 | 7.9 |
| 20 | 3 | 4 | Clyde Bruckman’s Final Repose | 13 Oct 1995 | 9.2 |
| 21 | 5 | 1 | Redux | 02 Nov 1997 | 8.8 |
| 22 | 5 | 2 | Redux II | 09 Nov 1997 | 9.1 |
| 23 | 5 | 3 | Unusual Suspects | 16 Nov 1997 | 8.6 |
| 24 | 5 | 4 | Detour | 23 Nov 1997 | 8.3 |
| 25 | 6 | 1 | The Beginning | 08 Nov 1998 | 8.2 |
| 26 | 6 | 2 | Drive | 15 Nov 1998 | 8.5 |
| 27 | 8 | 1 | Within | 05 Nov 2000 | 8.4 |
| 28 | 8 | 2 | Without | 12 Nov 2000 | 8.5 |
| 29 | 8 | 3 | Patience | 19 Nov 2000 | 7.8 |
| 30 | 8 | 4 | Roadrunners | 26 Nov 2000 | 8.3 |
| 31 | 8 | 5 | Invocation | 03 Dec 2000 | 7.9 |
| 32 | 8 | 6 | Redrum | 10 Dec 2000 | 8.4 |
| 33 | 8 | 7 | Via Negativa | 17 Dec 2000 | 7.9 |
| 34 | 8 | 8 | Surekill | 07 Jan 2001 | 7.2 |
| 35 | 9 | 1 | Nothing Important Happened Today | 11 Nov 2001 | 7.7 |
| 36 | 9 | 2 | Nothing Important Happened Today II | 18 Nov 2001 | 7.7 |
| 37 | 9 | 3 | Damonicus | 02 Dec 2001 | 7.5 |
| 38 | 9 | 4 | 4-D | 09 Dec 2001 | 8.0 |
| 39 | 9 | 5 | Lord of the Flies | 16 Dec 2001 | 7.0 |
| 40 | 9 | 6 | Trust No 1 | 06 Jan 2002 | 7.8 |
| 41 | 9 | 7 | John Doe | 13 Jan 2002 | 7.8 |
| 42 | 9 | 8 | Hellbound | 27 Jan 2002 | 7.5 |
| 43 | 9 | 9 | Provenance | 03 Mar 2002 | 7.9 |
| 44 | 9 | 10 | Providence | 10 Mar 2002 | 7.7 |
| 45 | 9 | 11 | Audrey Pauley | 17 Mar 2002 | 7.9 |
| 46 | 9 | 12 | Underneath | 31 Mar 2002 | 7.3 |
| 47 | 9 | 13 | Improbable | 07 Apr 2002 | 7.6 |
| 48 | 9 | 14 | Scary Monsters | 14 Apr 2002 | 7.6 |
| 49 | 9 | 15 | Jump the Shark | 21 Apr 2002 | 7.7 |
| 50 | 9 | 16 | William | 28 Apr 2002 | 8.0 |
| 51 | 9 | 17 | Release | 05 May 2002 | 8.4 |
| 52 | 9 | 18 | Sunshine Days | 12 May 2002 | 7.9 |
| 53 | 9 | 19 | The Truth: Parts 1 & 2 | 19 May 2002 | 8.4 |
Well, we have an issue. This API does not seem to have information for a variety of episodes and missing whole seasons. So what is next? Going right to the source, IMDB Interfaces. Downloading the ratings.list file from the provided FTP, we will attempt to parse the information from there.
IMDB Data
Opening the downloaded file in a Notepad++, we can see that it does have X Files under the Movie Ratings Report heading
# New Distribution Votes Rank Title
# 0000013201 1294 7.5 "The X Files" (1993) {2Shy (#3.6)}So, lets try to read this in and extract the information:
imdb.text <- readLines("C:\\code\\web\\2015-05-18-XFiles-Season-Rating/ratings.list")
# Filter off only the X Files series, Want -> The X Files, tv series end with "}"
imdb.xf <- imdb.text[grepl("The X Files", imdb.text) & grepl("}", imdb.text)]
head(imdb.xf)## [1] " 0000013201 1294 7.5 \"The X Files\" (1993) {2Shy (#3.6)}"
## [2] " 0000122101 1550 6.6 \"The X Files\" (1993) {3 (#2.7)}"
## [3] " 0000002212 802 8.0 \"The X Files\" (1993) {4-D (#9.4)}"
## [4] " 0000001133 1343 8.8 \"The X Files\" (1993) {731 (#3.10)}"
## [5] " 0000012211 1043 7.5 \"The X Files\" (1993) {Agua Mala (#6.13)}"
## [6] " 0000012211 1067 7.6 \"The X Files\" (1993) {All Souls (#5.17)}"Now we need to extract information, we dont care for anything but rating, episode name, season, and episode number:
# Remove leading white space and replace all white space by a single space
# sub replaces first occurance, gsub replaces all occurances
imdb.xf <- gsub("\\s+", " ", sub("^\\s+", "", imdb.xf))
imdb.xf <- gsub("\\)", "",gsub("\\(", "", imdb.xf)) # Remove () which makes later on easier
# Now want to get data into data frame
imdb.xf.df <- data.frame(rating=rep(NA, length(imdb.xf)), season=NA, episode=NA, title=NA, stringsAsFactors=F)
imdb.xf.df$rating <- as.numeric(sapply(strsplit(imdb.xf, " ", perl=T), "[[", 3)) # Get ratings, easy
# Get epi info
epi.info <- substr(imdb.xf, unlist(gregexpr(pattern="\\{", imdb.xf, perl=T))+1, unlist(gregexpr(pattern="\\}", imdb.xf, perl=T))-1)
# title and season/episode
imdb.xf.df$title <- substr(epi.info, 1, unlist(gregexpr(pattern="\\#", epi.info, perl=T))-2) # easy, break off of #
# Get season/epi
s.e.info <- substr(epi.info, unlist(gregexpr(pattern="\\#", epi.info, perl=T))+1, nchar(epi.info))
imdb.xf.df$season <- substr(s.e.info, 1,unlist(gregexpr(pattern="\\.", s.e.info, perl=T))-1)
imdb.xf.df$episode <- as.numeric(substr(s.e.info, unlist(gregexpr(pattern="\\.", s.e.info, perl=T))+1, nchar(s.e.info)))
# order info
imdb.xf.df <- imdb.xf.df[order(imdb.xf.df$season, imdb.xf.df$episode),]
imdb.xf.df$id <- 1:nrow(imdb.xf.df)#Graphing Information
Now since using the IMDB ratings, we can plot the information.
library(ggplot2)
ggplot(imdb.xf.df, aes(x=id, y = rating, colour=season, group=season)) + geom_line(size=1) + geom_point(size=4, shape=21, fill="white") + xlab("") + scale_colour_brewer(palette="Paired") 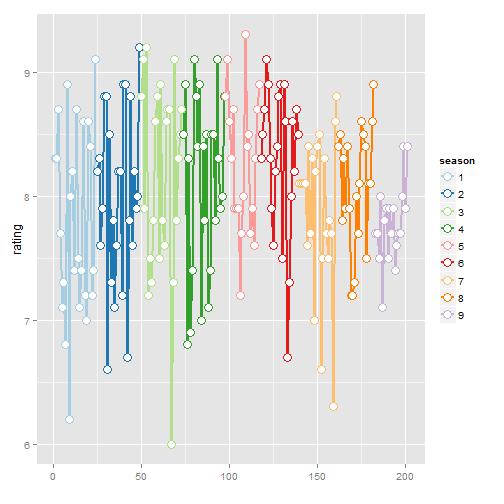
ggplot(imdb.xf.df, aes(x=season, y = rating, colour=season, group=season)) + geom_boxplot() + scale_colour_brewer(palette="Paired") + xlab("")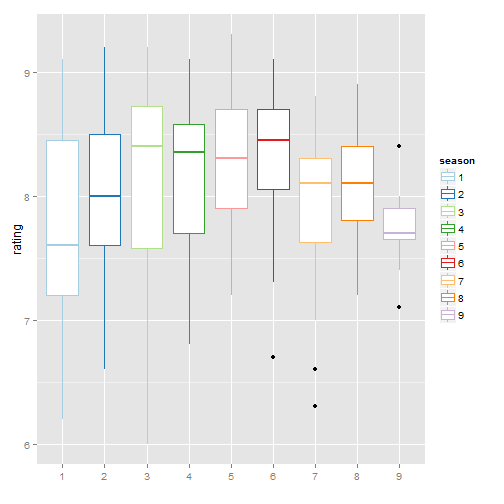
Quick Information
The top 6 episodes:
| rating | season | episode | title |
|---|---|---|---|
| 9.3 | 5 | 12 | Bad Blood |
| 9.2 | 2 | 25 | Anasazi |
| 9.2 | 3 | 4 | Clyde Bruckman’s Final Repose |
| 9.1 | 1 | 23 | The Erlenmeyer Flask |
| 9.1 | 3 | 2 | Paper Clip |
| 9.1 | 3 | 20 | Jose Chung’s ‘From Outer Space’ |
The worst 6 episode:
| rating | season | episode | title |
|---|---|---|---|
| 6.7 | 6 | 16 | Alpha |
| 6.6 | 2 | 7 | 3 |
| 6.6 | 7 | 13 | First Person Shooter |
| 6.3 | 7 | 20 | Fight Club |
| 6.2 | 1 | 8 | Space |
| 6.0 | 3 | 18 | Teso dos Bichos |
Conclusion
Remember to use to original source of data as much as possible!!!