James Bond Movie Ratings and Box Office
Introduction
With Spectre due to be released soon, I wanted to take a look at old Bond movies and how well they were received on IMDB and the box office totals. To do this, the RVest and Selector Gadget package and plug in was used to collect data from the Wikipedia list of James Bond films. This solves the problem of adjusting for inflation and provides information about actor and release year very easily in a table.
Data
Using the RVest and Selector Gadget plugin as I’ve outlined in a previous post, the table can be read in easily as was done below.
library(rvest)
website <- "https://en.wikipedia.org/wiki/List_of_James_Bond_films"
bond_wiki <- html(website)
# Get first table
bondTable <- html_table(bond_wiki, fill=T)[[1]]
# Look at table
kable(bondTable, align='c')| Title | Year | Bond actor | Director | Box office | Budget | Salary of Bond actor | Box office | Budget | Salary of Bond actor |
|---|---|---|---|---|---|---|---|---|---|
| Actual $ (millions)[18][19] | NA | NA | Adjusted 2005 $ (millions)[19] | NA | NA | NA | NA | NA | NA |
| Dr. No | 1962 | Connery, SeanSean Connery | Young, TerenceTerence Young | 59.5 | 1.1 | 0.1 | 448.8 | 7.0 | 0.6 |
| From Russia with Love | 1963 | Connery, SeanSean Connery | Young, TerenceTerence Young | 78.9 | 2.0 | 0.3 | 543.8 | 12.6 | 1.6 |
| Goldfinger | 1964 | Connery, SeanSean Connery | Hamilton, GuyGuy Hamilton | 124.9 | 3.0 | 0.5 | 820.4 | 18.6 | 3.2 |
| Thunderball | 1965 | Connery, SeanSean Connery | Young, TerenceTerence Young | 141.2 | 6.8 | 0.8 | 848.1 | 41.9 | 4.7 |
| You Only Live Twice | 1967 | Connery, SeanSean Connery | Gilbert, LewisLewis Gilbert | 101.0 | 10.3 | 0.8 + 25% net merch royalty | 514.2 | 59.9 | 4.4 excluding profit participation |
| On Her Majesty’s Secret Service | 1969 | Lazenby, GeorgeGeorge Lazenby | Hunt, Peter R.Peter R. Hunt | 64.6 | 7.0 | 0.1 | 291.5 | 37.3 | 0.6 |
| Diamonds Are Forever | 1971 | Connery, SeanSean Connery | Hamilton, GuyGuy Hamilton | 116.0 | 7.2 | 1.2 + 12.5% of gross (14.5) | 442.5 | 34.7 | 5.8 excluding profit participation |
| Live and Let Die | 1973 | Moore, RogerRoger Moore | Hamilton, GuyGuy Hamilton | 126.4 | 7.0 | n/a | 460.3 | 30.8 | n/a |
| man with !The Man with the Golden Gun | 1974 | Moore, RogerRoger Moore | Hamilton, GuyGuy Hamilton | 98.5 | 7.0 | n/a | 334.0 | 27.7 | n/a |
| spy who !The Spy Who Loved Me | 1977 | Moore, RogerRoger Moore | Gilbert, LewisLewis Gilbert | 185.4 | 14.0 | n/a | 533.0 | 45.1 | n/a |
| Moonraker | 1979 | Moore, RogerRoger Moore | Gilbert, LewisLewis Gilbert | 210.3 | 34.0 | n/a | 535.0 | 91.5 | n/a |
| For Your Eyes Only | 1981 | Moore, RogerRoger Moore | Glen, JohnJohn Glen | 194.9 | 28.0 | n/a | 449.4 | 60.2 | n/a |
| Octopussy | 1983 | Moore, RogerRoger Moore | Glen, JohnJohn Glen | 183.7 | 27.5 | 4.0 | 373.8 | 53.9 | 7.8 |
| view !A View to a Kill | 1985 | Moore, RogerRoger Moore | Glen, JohnJohn Glen | 152.4 | 30.0 | 5.0 | 275.2 | 54.5 | 9.1 |
| living !The Living Daylights | 1987 | Dalton, TimothyTimothy Dalton | Glen, JohnJohn Glen | 191.2 | 40.0 | 3.0 | 313.5 | 68.8 | 5.2 |
| Licence to Kill | 1989 | Dalton, TimothyTimothy Dalton | Glen, JohnJohn Glen | 156.2 | 36.0 | 5.0 | 250.9 | 56.7 | 7.9 |
| GoldenEye | 1995 | Brosnan, PiercePierce Brosnan | Campbell, MartinMartin Campbell | 351.9 | 60.0 | 4.0 | 518.5 | 76.9 | 5.1 |
| Tomorrow Never Dies | 1997 | Brosnan, PiercePierce Brosnan | Spottiswoode, RogerRoger Spottiswoode | 338.9 | 110.0 | 8.2 | 463.2 | 133.9 | 10.0 |
| world !The World Is Not Enough | 1999 | Brosnan, PiercePierce Brosnan | Apted, MichaelMichael Apted | 361.8 | 135.0 | 12.4 | 439.5 | 158.3 | 13.5 |
| Die Another Day | 2002 | Brosnan, PiercePierce Brosnan | Tamahori, LeeLee Tamahori | 431.9 | 142.0 | 16.5 | 465.4 | 154.2 | 17.9 |
| Casino Royale | 2006 | Craig, DanielDaniel Craig | Campbell, MartinMartin Campbell | 594.2 | 150.0 | 3.4 | 581.5 | 145.3 | 3.3 |
| Quantum of Solace | 2008 | Craig, DanielDaniel Craig | Forster, MarcMarc Forster | 576.0 | 200.0 | 8.9 | 514.2 | 181.4 | 8.1 |
| Skyfall | 2012 | Craig, DanielDaniel Craig | Mendes, SamSam Mendes | 1108.6[20] | 150.0[21][22]—200.0[20] | 17.0[23] | 879.8 | 158.1 | 13.5 |
| Spectre | 2015 | Craig, DanielDaniel Craig | Mendes, SamSam Mendes | ||||||
| Totals | NA | NA | NA | $5.9484 billion | $1.2579 billion | $11.2965 billion | $1.7039 billion |
Base Data from Wikipedia
From this, there is a number of problems to clean up.
- Remove first and last 2 rows of information that is not present or needed.
- Remove [].
- Remove columns that are not needed.
- Fix actor and director names.
- Remove data before ! in Title.
So fixing the first part is easy, specify rows to keep:
keepRows <- c(2:(nrow(bondTable)-2))
bondTable <- bondTable[keepRows,]The next part is to remove the square brackets. This can be done using gsub and the apply function.
bondTable <- apply(bondTable, 2, function(x) gsub("\\[", "", x))
bondTable <- apply(bondTable, 2, function(x) gsub("\\]", "", x))
# put back as data frame
bondTable <- data.frame(bondTable, stringsAsFactors=F)Removing the columns is just as easy as removing rows. From the Wikipedia page and our data frame:
names(bondTable)## [1] "Title" "Year"
## [3] "Bond.actor" "Director"
## [5] "Box.office" "Budget"
## [7] "Salary.of.Bond.actor" "Box.office.1"
## [9] "Budget.1" "Salary.of.Bond.actor.1"Matching this to Wikipedia:
- Title
- Year
- Bond.actor
- Director
- Box.office.1
- Budget.1
The .1 corresponds to prices adjusted inflation.
bondTable <- bondTable[,c(1,2,3,4,8,9)]Next is to remove the double of the names of Bond actor and the director. The easiest way I can think of is to read in the text attributes using rvest and extract the information. This will extract more information and will need to use our previous knowledge to extract only the correct information.
The result of the nodes “.fn a”, gives actor then director. Since there are 23 movies at the time of writing, the first 46 indices are all that is needed.
act.dir <- html_text(html_nodes(bond_wiki, ".fn a"))
# Num movies
num.movies <- nrow(bondTable)
bondTable$Bond.actor <- act.dir[seq(1, num.movies*2, 2)]
bondTable$Director <- act.dir[seq(2, num.movies*2, 2)]The resulting data frame now looks like this:
kable(bondTable, align='c')| Title | Year | Bond.actor | Director | Box.office.1 | Budget.1 | |
|---|---|---|---|---|---|---|
| 2 | Dr. No | 1962 | Sean Connery | Terence Young | 448.8 | 7.0 |
| 3 | From Russia with Love | 1963 | Sean Connery | Terence Young | 543.8 | 12.6 |
| 4 | Goldfinger | 1964 | Sean Connery | Guy Hamilton | 820.4 | 18.6 |
| 5 | Thunderball | 1965 | Sean Connery | Terence Young | 848.1 | 41.9 |
| 6 | You Only Live Twice | 1967 | Sean Connery | Lewis Gilbert | 514.2 | 59.9 |
| 7 | On Her Majesty’s Secret Service | 1969 | George Lazenby | Peter R. Hunt | 291.5 | 37.3 |
| 8 | Diamonds Are Forever | 1971 | Sean Connery | Guy Hamilton | 442.5 | 34.7 |
| 9 | Live and Let Die | 1973 | Roger Moore | Guy Hamilton | 460.3 | 30.8 |
| 10 | man with !The Man with the Golden Gun | 1974 | Roger Moore | Guy Hamilton | 334.0 | 27.7 |
| 11 | spy who !The Spy Who Loved Me | 1977 | Roger Moore | Lewis Gilbert | 533.0 | 45.1 |
| 12 | Moonraker | 1979 | Roger Moore | Lewis Gilbert | 535.0 | 91.5 |
| 13 | For Your Eyes Only | 1981 | Roger Moore | John Glen | 449.4 | 60.2 |
| 14 | Octopussy | 1983 | Roger Moore | John Glen | 373.8 | 53.9 |
| 15 | view !A View to a Kill | 1985 | Roger Moore | John Glen | 275.2 | 54.5 |
| 16 | living !The Living Daylights | 1987 | Timothy Dalton | John Glen | 313.5 | 68.8 |
| 17 | Licence to Kill | 1989 | Timothy Dalton | John Glen | 250.9 | 56.7 |
| 18 | GoldenEye | 1995 | Pierce Brosnan | Martin Campbell | 518.5 | 76.9 |
| 19 | Tomorrow Never Dies | 1997 | Pierce Brosnan | Roger Spottiswoode | 463.2 | 133.9 |
| 20 | world !The World Is Not Enough | 1999 | Pierce Brosnan | Michael Apted | 439.5 | 158.3 |
| 21 | Die Another Day | 2002 | Pierce Brosnan | Lee Tamahori | 465.4 | 154.2 |
| 22 | Casino Royale | 2006 | Daniel Craig | Martin Campbell | 581.5 | 145.3 |
| 23 | Quantum of Solace | 2008 | Daniel Craig | Marc Forster | 514.2 | 181.4 |
| 24 | Skyfall | 2012 | Daniel Craig | Sam Mendes | 879.8 | 158.1 |
The last step in cleaning up the data, is to remove the text before ! in the titles. I could not think of an easy and quick way to do this with an apply function so doing this with a loop and substr function.
idx <- grep("!", bondTable$Title)
if (length(idx) > 0) {
for (k in 1:length(idx)) {
str <- bondTable$Title[idx[k]]
bondTable$Title[idx[k]] <- substr(str, gregexpr("!", str)[[1]][1] + 1, nchar(str))
}
}This now gives us a cleaned data set to work on. The next part will be to merge with IMDB ratings of each movie.
IMDB Ratings
To get the IMDB ratings, a similar procedure will be followed as was done in a previous post about X-Files seaons. The database will be read in, but since we know the movie name and year, this will be searched for each movie and rating extracted.
fp <- "C:\\code\\web\\2015-05-18-XFiles-Season-Rating/ratings.list"
imdb.text <- readLines(fp)The way the IMDB text is read in, there is a lot of white space. So this will be removed to make extracting data easier.
imdb.text <- gsub("\\s+", " ", sub("^\\s+", "", imdb.text))The last bit of clean up is to remove TV shows, direct-to-video releases, and video games. TV shows either are labeled as (TV) or have {} in the string. Direct-to-videos are labeled as (V) and video games as (VG).
imdb.text <- imdb.text[!(grepl("\\{", imdb.text) & grepl("\\}", imdb.text))]
imdb.text <- imdb.text[!grepl("\\(TV\\)", imdb.text)]
imdb.text <- imdb.text[!grepl("\\(V\\)", imdb.text)]
imdb.text <- imdb.text[!grepl("\\(VG\\)", imdb.text)]Now need to find each movie and get rating. This will be done by using grep to match on name and year.
getRating <- function(movInfo, db) {
ratings <- -1 # Return negative rating if more than one match is found
tmp <- db[grepl(movInfo[1], db) & grepl(movInfo[2], db)]
if (length(tmp) == 1) {
ratings <- as.numeric(as.character(strsplit(tmp, " ")[[1]][3]))
}
return(ratings)
}
ratings <- apply(bondTable[, c('Title', 'Year')], 1, getRating, db=imdb.text)
# Check for multiple values
bondTable$Title[ratings == -1]## [1] "Thunderball"From the above, Thunderball has multiple entries, so lets find out what the multiples are.
imdb.text[grepl(bondTable$Title[ratings == -1], imdb.text) &
grepl(bondTable$Year[ratings == -1], imdb.text)]## [1] "4...6..... 5 3.4 Mr. Thunderball (1965)"
## [2] "0000013200 72457 7.0 Thunderball (1965)"From this, there are two movies with Thunderball in the title in 1965. It is easiest just to manually add this result to ratings.
ratings[ratings == -1] <- 7.0
bondTable$IMDB.Rating <- ratingsGraphing
Clean up some values to make it easier to plot.
bondTable$Bond.actor <- as.factor(bondTable$Bond.actor)
bondTable$Director <- as.factor(bondTable$Director)
bondTable$Box.office.1 <- as.numeric(bondTable$Box.office.1)
bondTable$Year <- as.numeric(bondTable$Year)Plotting the data using ggplot2 package:
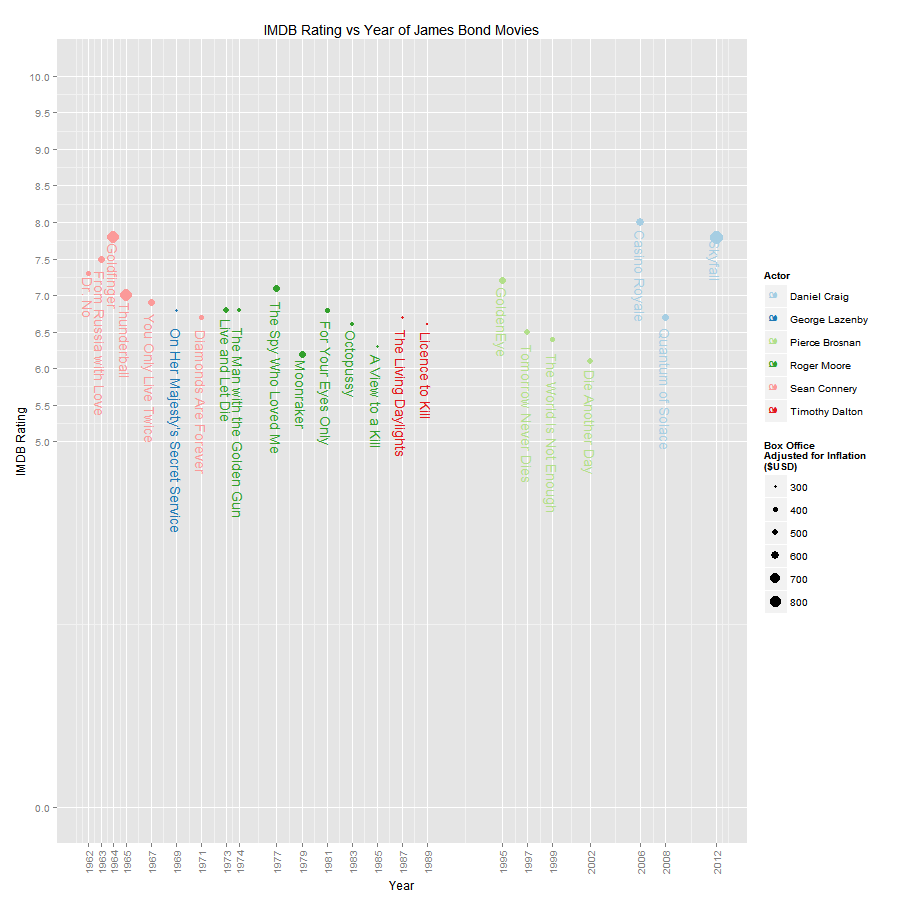
ggplot(bondTable, aes(x=Year, y=IMDB.Rating, color=Bond.actor, size=Box.office.1, label=Title)) +
geom_point() + geom_text(size=5, angle=-90, vjust=0.5, hjust=-0.09) +
guides(color=guide_legend(title="Actor"), size=guide_legend(title="Box Office\nAdjusted for Inflation\n($USD)")) +
scale_x_continuous(limits=c(min(bondTable$Year),max(bondTable$Year)), breaks=bondTable$Year) +
scale_y_continuous(limits=c(0, 10), breaks=c(0,seq(5,10,0.5))) +
theme(axis.text.x=element_text(angle=90,hjust=1,vjust=0.5,size=10)) +
scale_colour_brewer(palette="Paired") +
ylab("IMDB Rating") + ggtitle("IMDB Rating vs Year of James Bond Movies")